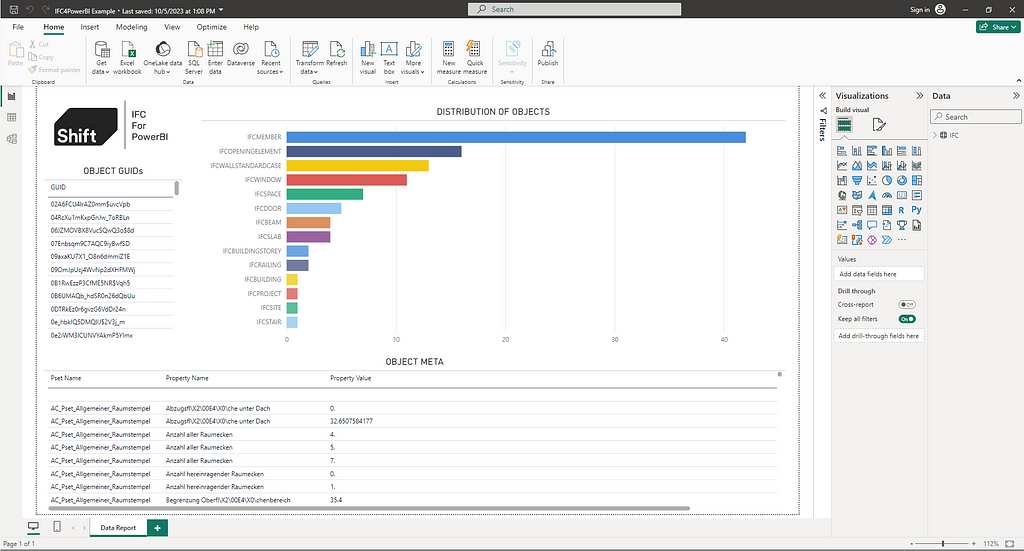
In this post I’m going to walk through the steps taken to extract the data from International Foundation Class (IFC) files to create the Shift IFC4PowerBI function available here on Github. We’re going to be focusing on the metadata in the file for now, but you can apply this same logic to extract the geometry if you were feeling adventurous. By understanding this workflow you might be able to incorporate IFC data into your own processes more easily.
File format
The first thing to understand about IFC files is that they are text files, very long and complex text files, but text files nevertheless. This is great from a data point of view as there are several types of native file you would typically encounter in the construction space:
– Text based files like IFC and P6 XML
– Database files such as Asta Powerproject files
– Binary files such as Revit or DWG
Text and Database files can be read using standard tools and brought into tools like PowerBI or incorporated into data workflows, whereas binary files are typically only interpreted by their source tool or other certified tools. That makes text based file formats a great solution for long term storage as we are not reliant on a particular bit of software to interrogate the data later. Microsoft’s free VSCode is my preferred tool for opening text based files, but you can always use notepad, notepadd++ or any other tools. Below you can see the screenshot a section of the IFC file available from Aachen University on Github:
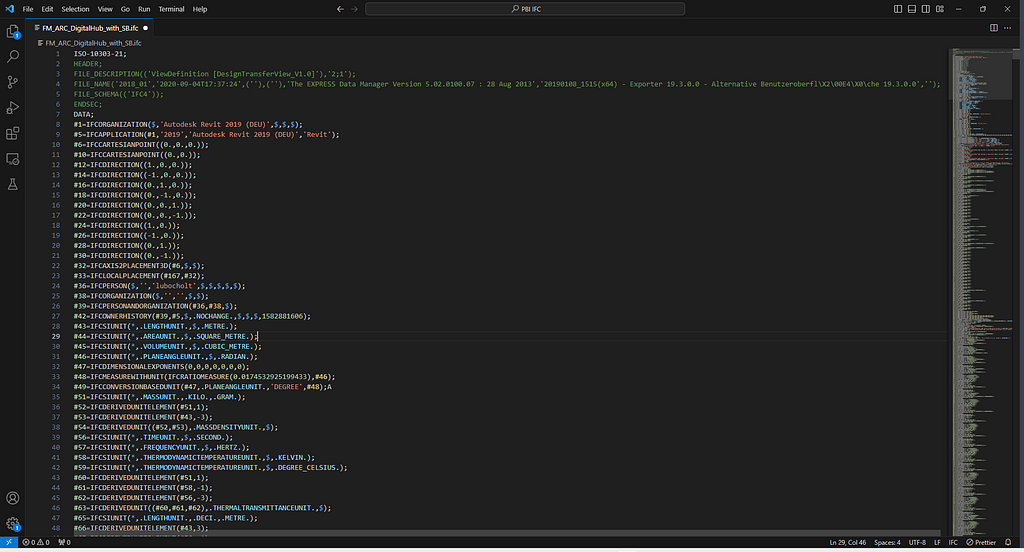
IFC files are written in a structure called EXPRESS which involves a whole bunch of lines referencing each other using their row numbers. There is some preamble relating to the file, but the brunt of the data is everything after that “DATA;” row.
Processing the IFC
The first step is to convert that data from simple rows into an intelligent table in PowerBI using the following PowerQuery:
let
Source = Table.FromColumns({Lines.FromBinary(#"IFC Binary", null, null, 1252)}),
// Split by Equal Sign
SplitByEquals = Table.SplitColumn(
Source,
"Column1",
Splitter.SplitTextByEachDelimiter({"="}, QuoteStyle.Csv, false),
{"Element ID", "Values"}
),
// Replace Single Quotes
ReplaceSingleQuotes = Table.ReplaceValue(
SplitByEquals,
"'",
"""",
Replacer.ReplaceText,
{"Values"}
),
// Trim Text
TrimValues = Table.TransformColumns(
ReplaceSingleQuotes,
{{"Values", Text.Trim, type text}, {"Element ID", Text.Trim, type text}}
),
// Filter Non-null Rows
FilterNonNullValues = Table.SelectRows(TrimValues, each ([Values] <> null)),
// Split by Open Parenthesis
SplitByOpenParenthesis = Table.SplitColumn(
FilterNonNullValues,
"Values",
Splitter.SplitTextByEachDelimiter({"("}, QuoteStyle.None, false),
{"Category", "Values"}
),
// Extract Data Before Close Parenthesis
ExtractBeforeCloseParenthesis = Table.TransformColumns(
SplitByOpenParenthesis,
{{"Values", each Text.BeforeDelimiter(_, ")", {0, RelativePosition.FromEnd}), type text}}
)
The basic steps taken are:
- Load the IFC file
- Split each row using the “=” sign as a delimiter. It is important on this step to in include the “QuoteStyle.csv” parameter in order to make sure any “=” included in the actual value of the row is ignored. This gives us a column with the row number and one with the contents of the row.
- Replace single quotes with double quotes, due to quirk with the way PowerBI understands quotes this helps us split the data later.
- Trimming the values helps us remove and leading or trailing spaces to keep everything neat and tidy.
- Filtering null values out to reliably remove any of the content that isn’t related to row data (you can chose to process this header data separately)
- Remove the leading and trailing brackets from the Values field.
Now we have a lovely clean data set showing the row number, the data category and the data values in that category.
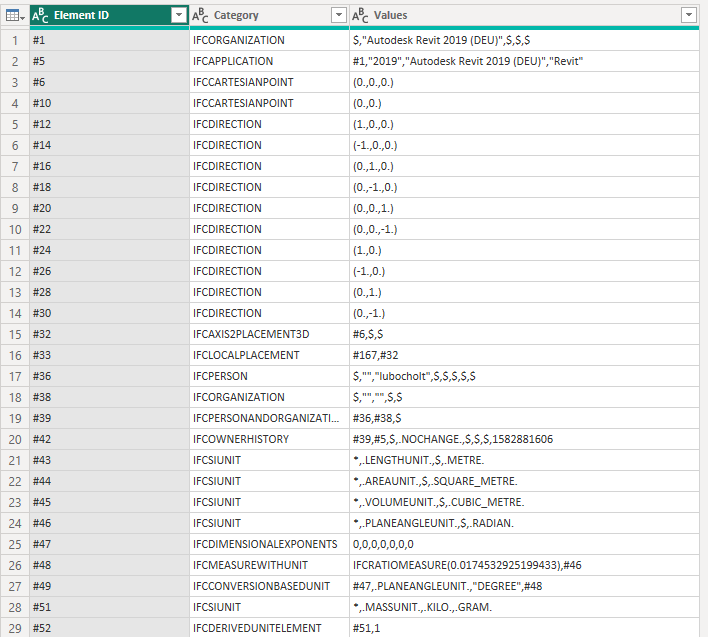
Since we are looking to process this file in the most efficient manner we are going to turn the data on it’s head a little.
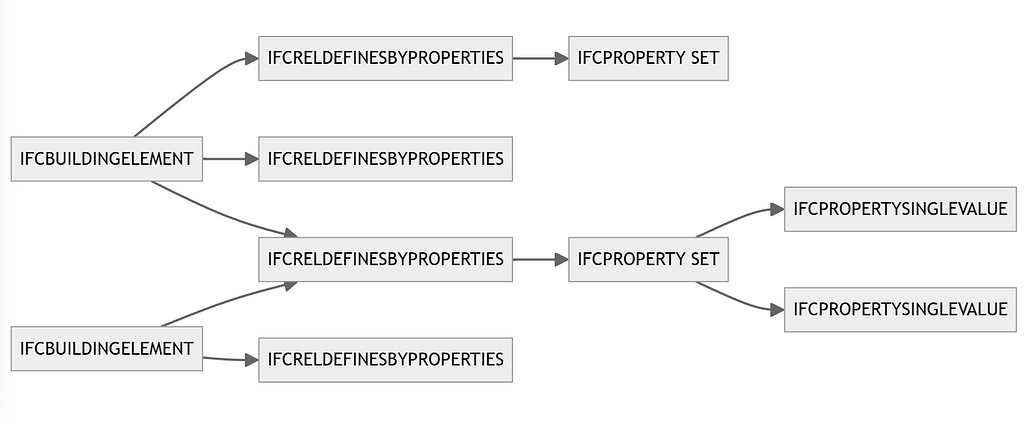
Since IFC data uses a one to many approach meaning that the same parameter can be applied to multiple parents it makes more sense to start with the parameters and work back to the geometric elements rather than looping through each element and reprocessing the same parameter multiple times
// Filtering & Transformation for IFCPROPERTYSINGLEVALUE
FilterSingleValue = Table.SelectRows(
ExtractBeforeCloseParenthesis,
each ([Category] = "IFCPROPERTYSINGLEVALUE")
),
SplitSingleValueDetails = Table.SplitColumn(
FilterSingleValue,
"Values",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
{"Property Name", "Property Description", "Property Value", "Property Unit"}
),
ExtractSingleValue = Table.TransformColumns(
SplitSingleValueDetails,
{{"Property Value", each Text.BetweenDelimiters(_, "(", ")"), type text}}
),
So we are going to start by filtering all of the IFCPROPERTYSINGLEVALUE rows, and from there:
- Split the values by the comma (remembering the QuoteStyle.csv from earlier) to get the Property Name, Description, Value, and Unit of measure.
- Extract the value from the Property Value column, at the moment we are not worried about the value type but we may come back and retrieve it in future versions to help with automatic calculations.
This leaves us with a nice set of properties:
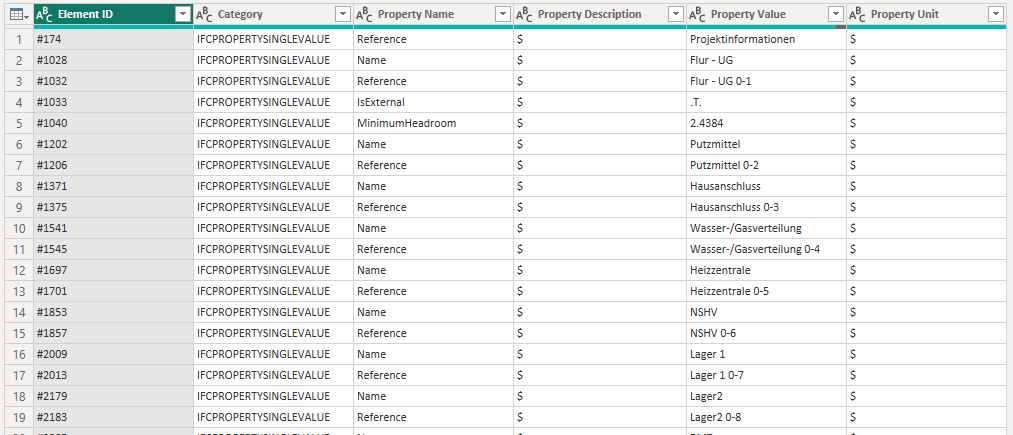
The interesting thing about PowerBI is that we can now go all the way back to our first step and continue from there, leaving this table in memory and recalling it later. So next up we do the same thing for the IFCPROPERTYSET values, merging in the IFCPROPERTYSINGLEVALUE table at the end:
// Filtering & Transformation for IFCPROPERTYSET
FilterPropertySet = Table.SelectRows(
ExtractBeforeCloseParenthesis,
each [Category] = "IFCPROPERTYSET"
),
ExtractPropertyID = Table.AddColumn(
FilterPropertySet,
"Property ID",
each Text.BetweenDelimiters([Values], "(", ")"),
type text
),
ExtractPsetName = Table.TransformColumns(
ExtractPropertyID,
{{"Values", each Text.BetweenDelimiters(_, ",", ",", 1, 0), type text}}
),
RemoveQuotes = Table.ReplaceValue(ExtractPsetName, """", "", Replacer.ReplaceText, {"Values"}),
ExpandPropertyID = Table.ExpandListColumn(
Table.TransformColumns(
RemoveQuotes,
{
{
"Property ID",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
let
itemType = (type nullable text) meta [Serialized.Text = true]
in
type {itemType}
}
}
),
"Property ID"
),
RenamePsetColumns = Table.RenameColumns(ExpandPropertyID, {{"Values", "Pset Name"}}),
JoinSingleValueAndPset = Table.NestedJoin(
RenamePsetColumns,
{"Property ID"},
ExtractSingleValue,
{"Element ID"},
"Properties",
JoinKind.LeftOuter
),
ExpandProperties = Table.ExpandTableColumn(
JoinSingleValueAndPset,
"Properties",
{"Property Name", "Property Value"},
{"Property Name", "Property Value"}
),
Then we do the same thing twice more to get all the way back to the IFCBUILDINGELEMENT and all of their children.
// Filtering & Transformation for IFCRELDEFINESBYPROPERTIES
FilterRelDefines = Table.SelectRows(
ExtractBeforeCloseParenthesis,
each [Category] = "IFCRELDEFINESBYPROPERTIES"
),
ExtractObjectID = Table.AddColumn(
FilterRelDefines,
"Object ID",
each Text.BetweenDelimiters([Values], "(", ")", {0, RelativePosition.FromEnd}, 0),
type text
),
ExtractPsetID = Table.TransformColumns(
ExtractObjectID,
{{"Values", each Text.AfterDelimiter(_, ",", {0, RelativePosition.FromEnd}), type text}}
),
RenameForRelDefines = Table.RenameColumns(ExtractPsetID, {{"Values", "Pset ID"}}),
ExpandObjectID = Table.ExpandListColumn(
Table.TransformColumns(
RenameForRelDefines,
{
{
"Object ID",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
let
itemType = (type nullable text) meta [Serialized.Text = true]
in
type {itemType}
}
}
),
"Object ID"
),
JoinRelDefinesAndPset = Table.NestedJoin(
ExpandObjectID,
{"Pset ID"},
ExpandProperties,
{"Element ID"},
"Property Sets",
JoinKind.LeftOuter
),
ExpandPropertySets = Table.ExpandTableColumn(
JoinRelDefinesAndPset,
"Property Sets",
{"Pset Name", "Property Name", "Property Value"},
{"Pset Name", "Property Name", "Property Value"}
),
// Final Join and Expansion
JoinMain = Table.NestedJoin(
ExpandPropertySets,
{"Object ID"},
ExtractBeforeCloseParenthesis,
{"Element ID"},
"Model",
JoinKind.LeftOuter
),
ExpandModel = Table.ExpandTableColumn(
JoinMain,
"Model",
{"Category", "Values"},
{"Ifc Type", "Values"}
),
FinalSplit = Table.SplitColumn(
ExpandModel,
"Values",
Splitter.SplitTextByDelimiter(",", QuoteStyle.Csv),
{"GUID"}
)
in
FinalSplit
The final table your left with is each property referencing all of its parents all the way up to the IFCGUID of the IFC element.
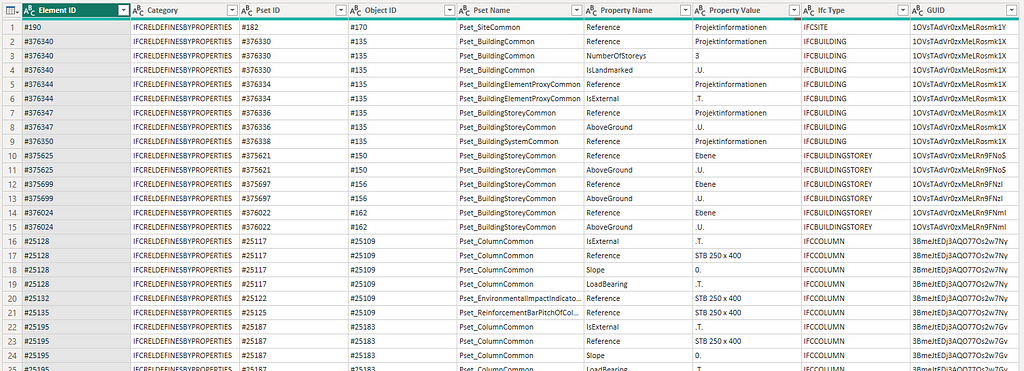
At this point you might be wondering why we have a long list of properties rather than a single row per item with the various parameters in columns. There are several reasons for this:
- It could result in an infinite number of columns depending on the IFC file
- You can no longer encorperate Property Sets into the data set
- It is much easier to filter and leverage the data inside the dashboard
The final thing involved in releasing the project was turning it into a function using the “let” instruction in PowerBI:
let
Source = (#"IFC File" as any) => let
// REST OF THE CODE GOES HERE
in
FinalSplit
in
Source
How to extract data from IFC files (in PowerBI) was originally published in Shift Construction on Medium, where people are continuing the conversation by highlighting and responding to this story.