Here is a link to the online prototype if you want to try it out yourself.
Introduction
In the new world of AI it can be quite hard to separate the hard problems from the easy problems. The advent of OpenAI’s ChatGPT opened the floodgates for competing LLMs, both proprietary and open-source, changing the landscape and making things that were hard a lot more straightforward.
This series of articles aims to guide you through the process of creating a chatbot using the ChatGPT API. You’ll learn how to consult the Uniclass coding system and identify the right codes from product descriptions. The journey begins with a basic web-based search tool and progresses to the automatic classification of IFC model elements and even deciphering classifications from images.
The goal is to incrementally break down this complex topic, making it clearer and more approachable with each piece.
Why not just use ChatGPT?
A large language model (LLM) like ChatGPT operates on the principle of pattern matching at an extraordinary scale. It meticulously analyzes the structure and nuances of language from a vast dataset of text. Think of it as a highly sophisticated puzzle-solver that doesn’t just fit pieces together randomly but has learned from millions of examples how certain words, phrases, and sentences are typically combined. By recognizing these patterns, the model can predict and generate text that mirrors natural human language, responding to prompts in a way that feels familiar and often remarkably accurate. This pattern recognition is the core of its ability to understand context, make associations, and even emulate reasoning based on the textual patterns it has encountered during its training.
ChatGPT can write code with a great level of success, and that is because the training data it used contained a huge corpus of published code from the like of Github, StackOverflow and more. In Construction we hold our cards much closer to our chest so there is far less data in the wild and with less data it is harder for the machine to have confidence in the data due to a lack of consistency. So what you end up with is something that could be read as a correct answer, but is actually wrong.
So in order to augment it with actual data that we know to be true, we are going to use a Retrieval-Augmented Generation (RAG) model. This is a type of AI that enhances text generation with an additional step of information retrieval. When prompted with a query, the RAG model first searches a large dataset to find relevant information. Then, using this context, it generates a response that integrates the retrieved data. This approach ensures that the responses are not only contextually relevant but also informed by up-to-date and specific information, leading to more accurate and precise answers.
Prerequisites
Before we get started I want a quick run through of the tools we’re going to use so you know if this tutorial is for you. I will assume a base level of understanding and refer to helpful documentation as we go, so even if you don’t know anything about Python or LLMs already but are curious to learn, don’t worry.
- Python for the general scripting and backed for our application
- Streamlit a front-end tool for Python which also offers a generous free hosting option to get us started
- Pinecone another tool with a generous free tier which will serve as the database for our Uniclass codes. You can swap in any vertex database of your chosing.
- ChatGPT API in order to catalogue the codes and retrieve them based on a query we will use ChatGPT. You can substitute other LLMs including open source ones if you wish.
- VSCode is my code editor of choice, here is a great tutorial on setting it up with Python (Get Started Tutorial for Python in Visual Studio Code)
Getting the data
There is nothing better for your AI based projects than starting with a good set of data, and part of the reason I chose to create this tutorial on Uniclass is because the base data is available for free, so go ahead and download the Uniclass data from the link below:
📄 Download | Uniclass (thenbs.com)]
Create a new project file structure and save all of the XLSX files that relate to the coding structure:
As with all data projects, never assume anything about your data, open up each one of the files and make sure they follow the same structure and quickly scroll up and down to make sure there aren’t any anomalies. This can save you a lot of time in the future. If this it your first time doing a project like this I would suggest removing all but a couple of key spreadsheets like “Products” to avoid long waits in the processing.
Processing the Data
In order to show this as a more step-by-step process I’ll be outputting json files as we go to show progress.
The first thing we want to do is extract all of the data from those lovely consistent spreadsheet. I used the following Python script to output them as a single json file. You will need to install pandas an openpyxl to get this to work (Installing Packages — Python Packaging User Guide)
pip install openpyxl pandas
import os
import json
import pandas as pd
# Specify the directory where your .xlsx files are located
directory = "Source Data"
# List to hold all records from all tables
all_records = []
# Loop through every file in the directory
for filename in os.listdir(directory):
if filename.endswith(".xlsx"):
# Construct the full file path
file_path = os.path.join(directory, filename)
# Load the spreadsheet using pandas, treating all data as strings
try:
# Read the Excel file, skipping the first two rows, using the third row as header, and interpreting all data as strings
df = pd.read_excel(file_path, header=2, dtype=str)
# Drop any columns that are entirely empty strings
df.replace('', pd.NA, inplace=True)
df.dropna(axis=1, how='all', inplace=True)
# Convert the dataframe to a list of dictionaries
records = df.to_dict(orient='records')
# Add "table" key and process each record
cleaned_records = []
for record in records:
# Only include key-value pairs where the value is not missing
cleaned_record = {k: v for k, v in record.items() if pd.notna(v)}
# Update the keys to be lowercase with underscores instead of spaces for consistency
cleaned_record = {k.lower().replace(' ', '_'): v for k, v in cleaned_record.items()}
# Add the "table" key by extracting the first two letters from the "code" column
# This is to make sure the case is consistent across the tables
if 'code' in cleaned_record: # Now it's lowercase, so 'Code' should be 'code'
cleaned_record['table'] = cleaned_record['code'][:2]
cleaned_records.append(cleaned_record)
# Append these records to the all_records list
all_records.extend(cleaned_records)
print(f"Processed {filename}")
except Exception as e:
print(f"Error processing {filename}: {e}")
# Save all records into a JSON file
json_filename = 'all_records.json'
with open(json_filename, 'w', encoding='utf-8') as jsonf:
json.dump(all_records, jsonf, ensure_ascii=False, indent=4)
print(f"All records have been saved into {json_filename}")
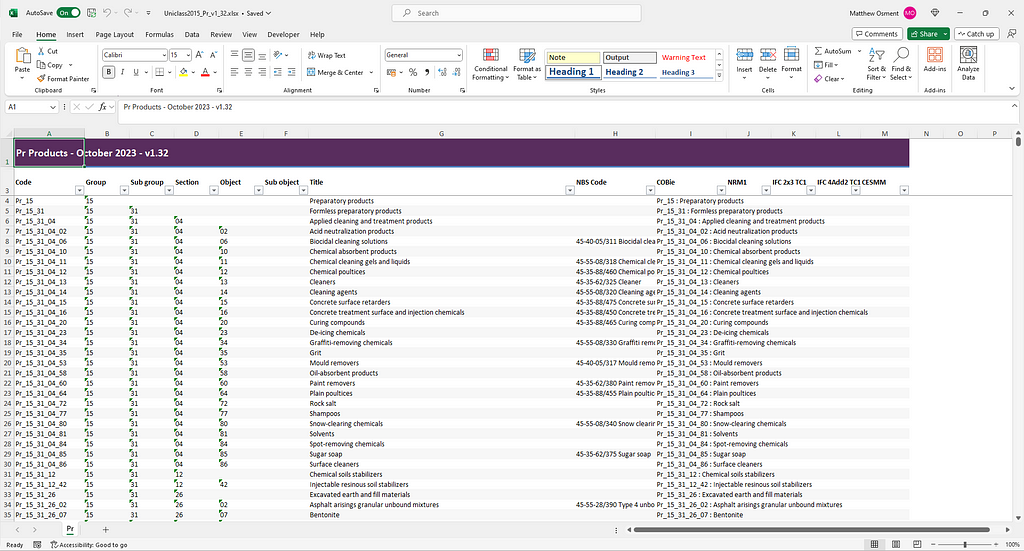
Now if you open up that all_records.json file you can see every individual Uniclass code as it’s own record. There’s just one hitch; the children don’t reference their parents. In the screenshot below I can see that Pr_40_70_51_30 is Fermenters, but I don’t know that Fermenters is a child of Medical and Laboratory Equipment, itself a child of Equipment and so on. This is important data as you could see how an LLM might get confused between Fermenters and Compost bins if it didn’t know one was medical and the other was a bin.
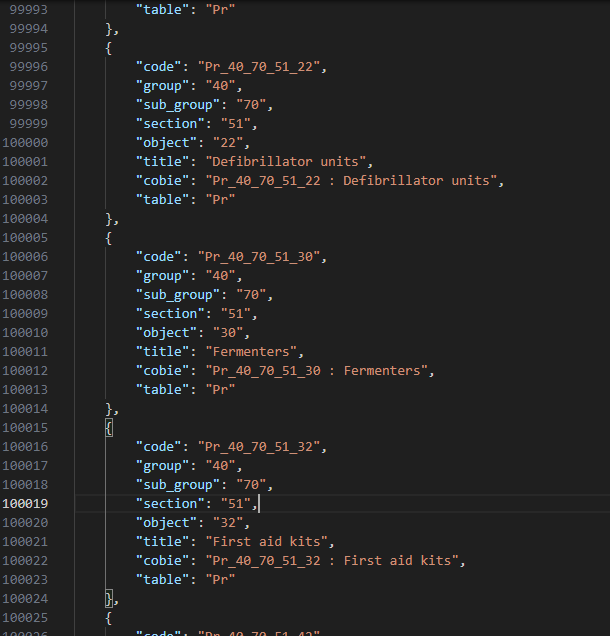
In order to rectify this we are going to improve our script a little. Since we know the products are listed in order we simply have to remember the parents and apply them to all of the children, then as we step back up a level forget any of the parent that are no longer relevant. I also took the opportunity to include the title of the relevant tables, so “Pr” becomes “Products”. In the block below I’ve highlighted the new code that enables this, resulting in:
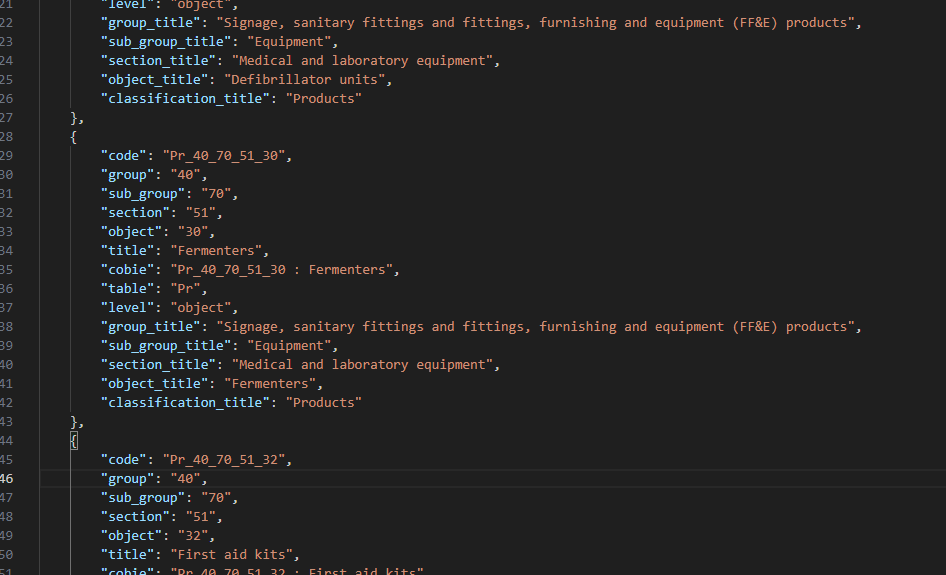
import os
import json
import pandas as pd
# Specify the directory where your .xlsx files are located
directory = "Source Data"
### NEW CODE ###
# Specify the heirarchy order
keys_hierarchy = ['group', 'sub_group', 'section', 'object', 'sub_object']
# Create a dictionary for storing parents
parent_records = {}
# Create the lookup for the classification type
classification_dicitonary = {'CO': 'Complexes',
'EF': 'Elements/ functions',
'EN': 'Entities',
'FI': 'Form of information',
'MA': 'Materials',
'PC': 'Properties and characteristics',
'PM': 'Project management',
'PR': 'Products',
'RK': 'Risk',
'RO': 'Roles',
'SL': 'Spaces/ locations',
'SS': 'Systems',
'TE': 'Tools and equipment',
'ZZ': 'CAD',
'AC': 'Activities'}
### NEW CODE ###
# List to hold all records from all tables
all_records = []
# Loop through every file in the directory
for filename in os.listdir(directory):
if filename.endswith(".xlsx"):
# Construct the full file path
file_path = os.path.join(directory, filename)
# Load the spreadsheet using pandas, treating all data as strings
try:
# Read the Excel file, skipping the first two rows, using the third row as header, and interpreting all data as strings
df = pd.read_excel(file_path, header=2, dtype=str)
# Drop any columns that are entirely empty strings
df.replace('', pd.NA, inplace=True)
df.dropna(axis=1, how='all', inplace=True)
# Convert the dataframe to a list of dictionaries
records = df.to_dict(orient='records')
# Add "table" key and process each record
cleaned_records = []
for record in records:
# Only include key-value pairs where the value is not missing
cleaned_record = {k: v for k, v in record.items() if pd.notna(v)}
# Update the keys to be lowercase with underscores instead of spaces for consistency
cleaned_record = {k.lower().replace(' ', '_'): v for k, v in cleaned_record.items()}
# Add the "table" key by extracting the first two letters from the "code" column
# This is to make sure the case is consistent across the tables
if 'code' in cleaned_record: # Now it's lowercase, so 'Code' should be 'code'
cleaned_record['table'] = cleaned_record['code'][:2]
### NEW CODE ###
# Identify the level of the record
for key in reversed(keys_hierarchy):
# Check if the key exists in the dictionary and has a non-null value
if key in cleaned_record and cleaned_record[key] is not None:
# Add the level to the dictionary
cleaned_record['level'] = key
# Add the title of this level to the parent records to use later
parent_records[key] = cleaned_record['title']
break
for key in keys_hierarchy:
# Check what levels you need from the parent list
if key in cleaned_record:
if key != 'level' and cleaned_record[key] is not None:
# Add the level from the parent to the dictionary
cleaned_record[key + '_title'] = parent_records[key]
else:
break
# Add the Uniclass classification text string
upper_table = cleaned_record['table'].upper()
classification_title = classification_dicitonary.get(upper_table, None)
if classification_title is not None:
cleaned_record['classification_title'] = classification_title
### NEW CODE ###
cleaned_records.append(cleaned_record)
# Append these records to the all_records list
all_records.extend(cleaned_records)
print(f"Processed {filename}")
except Exception as e:
print(f"Error processing {filename}: {e}")
# Save all records into a JSON file
json_filename = 'all_records.json'
with open(json_filename, 'w', encoding='utf-8') as jsonf:
json.dump(all_records, jsonf, ensure_ascii=False, indent=4)
print(f"All records have been saved into {json_filename}")
Setting up the database
Now we have our nice consistent Uniclass data in json format we are going to feed it into our database via OpenAI using something called Embeddings. These refer to a method of converting the vast and complex landscape of words, sentences, or even entire documents into a more manageable form known as vectors. These vectors are arrays of numbers that capture the essence of the text, representing its meaning and contextual relationships in a multi-dimensional space. By translating text into this numerical form, AI models can perform mathematical operations on words or phrases, effectively measuring and comparing their similarities and differences. This allows the model to discern patterns, group similar concepts, or even understand sequences within the data, making embeddings a fundamental component in natural language processing and understanding.
If you don’t already have an OpenAI and Pinecone.io account, now would be the time to set one up.
In Pinecone:
- Head to the dashboard and create a new index (this is their term for a dataset)
- Your Dimensions should be 1536 as this is the length of the vertices list that OpenAI produces
- Use the “starter” pod to remain on the free tier. (If you don’t query your data for > 7 days your index will be deleted, so be warned)
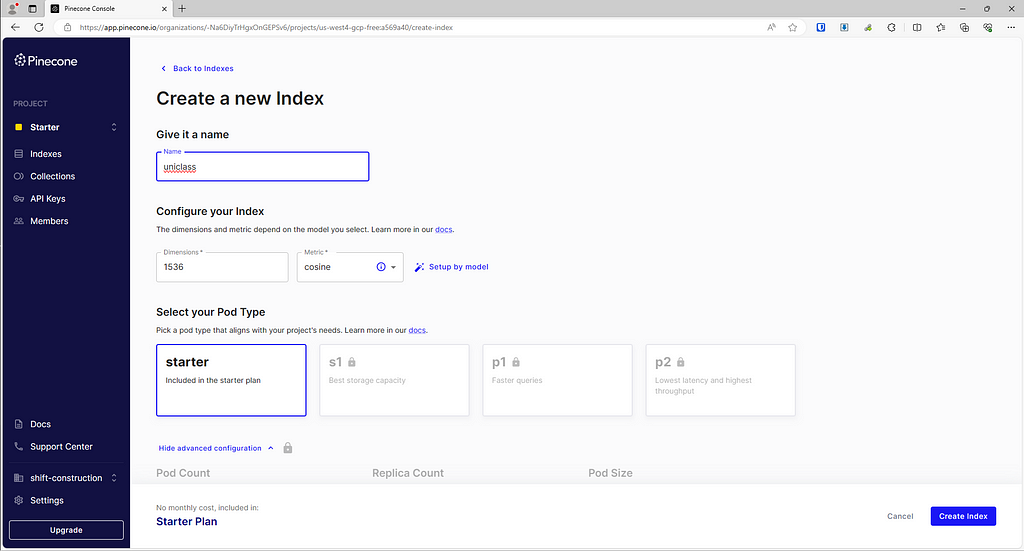
Now that you have your index set up, make a note of your host (eg. https://xyz-a5569a40.svc.us-west4-gcp-free.pinecone.io) and your API key for later. Now head over to API keys — OpenAI API and create a new OpenAI API key for this project and note that down too.
Loading the data
Now we have our database, our LLM and our data all ready we just need to piece them together. In order for the Embedding we create to be useful we need to reconfigure our Uniclass data to something more akin to language than data.
So the following Fermenters data might become “products described as ‘Fermenters’ which are classified by section ‘Medical and laboratory equipment’ in the sub group of ‘Equipment’ within the group ‘Signage, sanitary fittings and fittings, furnishing and equipment (FF&E) products’”
{
"code": "Pr_40_70_51_30",
"group": "40",
"sub_group": "70",
"section": "51",
"object": "30",
"title": "Fermenters",
"cobie": "Pr_40_70_51_30 : Fermenters",
"table": "Pr",
"level": "object",
"group title": "Signage, sanitary fittings and fittings, furnishing and equipment (FF&E) products",
"sub_group title": "Equipment",
"section title": "Medical and laboratory equipment",
"object title": "Fermenters",
"classification_title": "Products"
}
The python approach to this would look something like this:
import json
# Function to create a sentence from a dictionary
def create_sentence(d):
sentence_parts = []
if "classification_title" in d:
sentence_parts.append(f"{d['classification_title']}s described as")
if "sub_object_title" in d:
sentence_parts.append(f"'{d['sub_object_title']}' which are a sub group of")
if "object_title" in d:
sentence_parts.append(f"'{d['object_title']}' which are classified by section")
if "section_title" in d:
sentence_parts.append(f"'{d['section_title']}' in the sub group of")
if "sub_group_title" in d:
sentence_parts.append(f"'{d['sub_group_title']}' within the group")
if "group_title" in d:
sentence_parts.append(f"'{d['group_title']}'")
return ' '.join(sentence_parts)
# Read the json file
with open('all_records.json', 'r', encoding='utf-8') as file:
records = json.load(file)
# Process each record to create the sentence
sentences_data = []
for record in records:
sentence = create_sentence(record)
# Include the 'code' from the original record and the constructed sentence
sentences_data.append({
'code': record.get('code', 'N/A'), # 'N/A' as a default if 'code' does not exist
'sentence': sentence
})
# Save the sentences to a new json file
with open('sentences.json', 'w', encoding='utf-8') as file:
json.dump(sentences_data, file, ensure_ascii=False, indent=4)
print("Sentences have been successfully saved to 'sentences.json'.")
So now we need to combine that with the OpenAI and Pinecone APIs to populate the database.
import json
import os
import requests
import time
import random
count =0
# Load the OpenAI API key from an environment variable
openai_api_key = ''
pinecone_api_key = ''
pinecone_index_url = ''
# Constants for retry logic
MAX_RETRIES = 5
BACKOFF_FACTOR = 2
# Function to create a sentence from a dictionary
def create_sentence(d):
sentence_parts = []
if "classification_title" in d:
sentence_parts.append(f"{d['classification_title']}s described as")
if "sub_object_title" in d:
sentence_parts.append(f"'{d['sub_object_title']}' which are a sub group of")
if "object_title" in d:
sentence_parts.append(f"'{d['object_title']}' which are classified by section")
if "section_title" in d:
sentence_parts.append(f"'{d['section_title']}' in the sub group of")
if "sub_group_title" in d:
sentence_parts.append(f"'{d['sub_group_title']}' within the group")
if "group_title" in d:
sentence_parts.append(f"'{d['group_title']}'")
return ' '.join(sentence_parts)
# Function to get embeddings from OpenAI
def get_openai_embedding(text):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {openai_api_key}"
}
data = {
"input": text,
"model": "text-embedding-ada-002"
}
for attempt in range(MAX_RETRIES):
response = requests.post('https://api.openai.com/v1/embeddings', headers=headers, json=data)
if response.status_code == 200:
count = count +1
print(count)
return response.json()['data'][0]['embedding']
elif response.status_code == 429 or response.status_code >= 500:
# If rate limited or server error, wait and retry
print("try again in a bit")
time.sleep((BACKOFF_FACTOR ** attempt) + random.uniform(0, 1))
else:
# For other errors, raise exception without retrying
raise Exception(f"OpenAI API error: {response.text}")
raise Exception(f"OpenAI API request failed after {MAX_RETRIES} attempts")
def send_to_pinecone(batch):
headers = {
"Api-Key": pinecone_api_key,
"Content-Type": "application/json"
}
data = {
"vectors": batch,
"namespace": "uniclass_codes"
}
for attempt in range(MAX_RETRIES):
response = requests.post(f"https://{pinecone_index_url}/vectors/upsert", headers=headers, json=data)
if response.status_code == 200:
return response.json()
elif response.status_code == 429 or response.status_code >= 500:
# If rate limited or server error, wait and retry
time.sleep((BACKOFF_FACTOR ** attempt) + random.uniform(0, 1))
else:
# For other errors, raise exception without retrying
raise Exception(f"Pinecone API error: {response.text}")
raise Exception(f"Pinecone API request failed after {MAX_RETRIES} attempts")
# Process the records and batch them for Pinecone
batch = []
error_log = []
with open('all_records.json', 'r', encoding='utf-8') as file:
records = json.load(file)
for record in records:
try:
sentence = create_sentence(record)
embedding = get_openai_embedding(sentence)
# Create the dictionary as specified
new_record = {
"id": record.get('code', 'N/A'),
"values": embedding,
"metadata": record
}
batch.append(new_record)
# If we've reached a batch of 50, send it to Pinecone
if len(batch) >= 50:
send_to_pinecone(batch)
print("batch sent")
batch = [] # Reset the batch
except Exception as e:
error_log.append(str(e))
# Send any remaining records in the last batch if it's not empty
if batch:
try:
send_to_pinecone(batch)
except Exception as e:
error_log.append(str(e))
# Write the error log to a file
with open('error_log.txt', 'w') as log_file:
for error in error_log:
log_file.write(error + '\n')
if not error_log:
print("All records have been successfully processed and sent to Pinecone.")
else:
print("Some records may not have been processed due to errors. See 'error_log.txt' for details.")
This will take quite a while to process so I would advise looking into using the concurrent futures module in Python to add some parallelism to the process.
The Frontend
Now I have my data set up I just need to set up a simple front end for my MVP, as mentioned before I’ll use Streamlit for this. I need to scaffold out a logo and header text, a search box, and a results table for it to populate the top 10 results. For more information on setting up Streamlit apps, check out the tutorials on their website (Tutorials — Streamlit Docs)
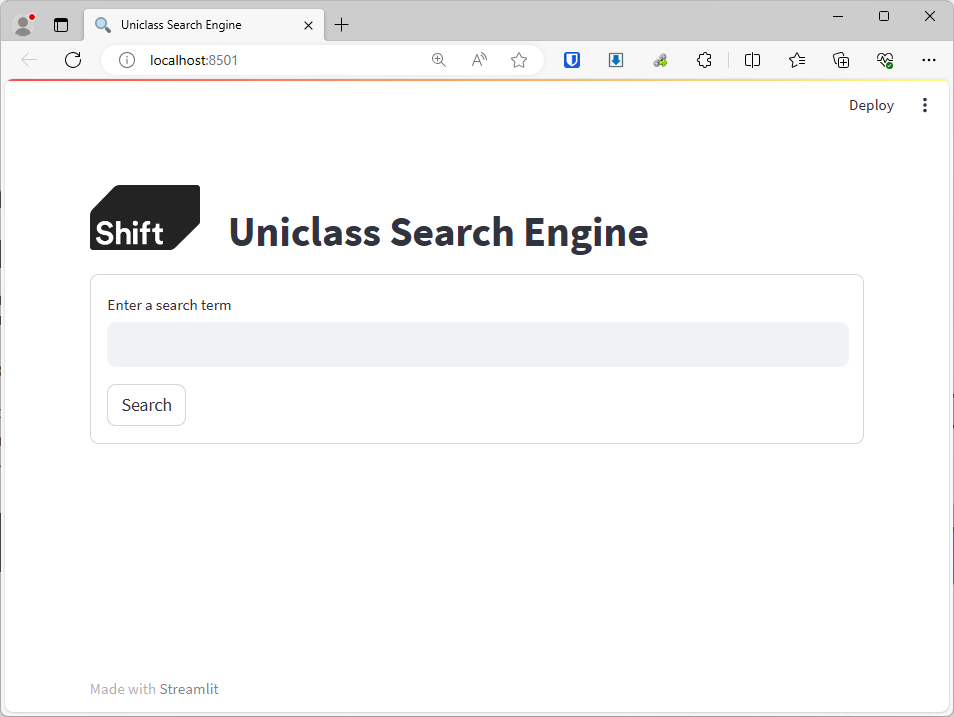
Save the following code as uniclass_search.py file and then open up a command prompt, making sure the directory is set to wherever your python file is, and type streamlit run uniclass_search.py. You’ll be given a URL which you can open to see your new app running locally.
import streamlit as st
# Function to simulate search and return results
def search(query):
# Dummy data
results = [
{'code': '001', 'title': 'Title One'},
{'code': '002', 'title': 'Title Two'},
{'code': '003', 'title': 'Title Three'},
]
# Filter results based on query (case insensitive)
filtered_results = [result for result in results if query.lower() in result['title'].lower()]
# Return the first 10 results
return filtered_results[:10]
# Set up the Streamlit app
def main():
# Set page config to add a logo and set the page title
st.set_page_config(page_title="Uniclass Search Engine", page_icon=":mag:", layout="wide")
# Header with logo and title
col1, col2 = st.columns([1, 5])
with col1:
st.image("https://usercontent.one/wp/www.shift-construction.com/wp-content/uploads/2023/10/shift-grey-logo-white-text_small.png", width=100) # Replace with the path to your logo image
with col2:
st.title("Uniclass Search Engine")
# Search box
with st.form(key='search_form'):
search_query = st.text_input("Enter a search term", key="search_box")
submit_button = st.form_submit_button(label='Search')
# Display the results table if search was triggered
if submit_button or search_query:
results = search(search_query)
if results:
# Display results in a table
st.write("Search Results:")
for result in results:
st.write(f"Code: {result['code']} - Title: {result['title']}")
# You can also use a dataframe and st.table to show this in tabular form
else:
st.write("No results found for your query.")
if __name__ == "__main__":
main()
Now we need to hook up the OpenAI and Pinecone APIs. We will be doing the same thing as before, except this time instead of uploading the data to Pinecone, we’ll be using the OpenAI embedding to query the data set and get the top results.
import streamlit as st
import requests
import time
import random
import pandas as pd
# Constants
MAX_RETRIES = 3 # Maximum number of retries for the API call
BACKOFF_FACTOR = 2 # Factor to determine the backoff period
# Replace the following with your actual credentials and endpoint details
openai_api_key = ''
pinecone_api_key = ''
pinecone_index_url = ''
# Function to get the embedding from OpenAI
def get_openai_embedding(text):
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {openai_api_key}"
}
data = {
"input": text,
"model": "text-embedding-ada-002"
}
for attempt in range(MAX_RETRIES):
response = requests.post('https://api.openai.com/v1/embeddings', headers=headers, json=data)
if response.status_code == 200:
return response.json()['data'][0]['embedding']
elif response.status_code == 429 or response.status_code >= 500:
# If rate limited or server error, wait and retry
time.sleep((BACKOFF_FACTOR ** attempt) + random.uniform(0, 1))
else:
# For other errors, raise exception without retrying
raise Exception(f"OpenAI API error: {response.text}")
raise Exception(f"OpenAI API request failed after {MAX_RETRIES} attempts")
# Function to send the embedding to Pinecone and get the results
def query_pinecone(embedding):
headers = {
"Api-Key": pinecone_api_key,
"Content-Type": "application/json"
}
data = {
"vector": embedding,
"topK": 10,
"includeValues": False,
"includeMetadata": True,
"namespace": "uniclass_codes"
}
url = f"https://{pinecone_index_url}/query"
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
return response.json()['matches']
else:
raise Exception(f"Pinecone API error: {response.text}")
# Set up the Streamlit app
def main():
st.set_page_config(page_title="Uniclass Search Engine", page_icon=":mag:", layout="wide")
# Header with logo and title
col1, col2 = st.columns([1, 5])
with col1:
st.image("https://usercontent.one/wp/www.shift-construction.com/wp-content/uploads/2023/10/shift-grey-logo-white-text_small.png", width=100) # Replace with the path to your logo image
with col2:
st.title("Uniclass Search Engine")
# Search box
with st.form(key='search_form'):
search_query = st.text_input("Enter a search term", key="search_box")
submit_button = st.form_submit_button(label='Search')
# If search was triggered, get the embedding and then query Pinecone
if submit_button and search_query:
try:
embedding = get_openai_embedding(search_query)
results = query_pinecone(embedding)
if results:
# Display results in a table
st.write("Search Results:")
# Use a dataframe to display the results in a more tabular form
result_data = [{"code": match["metadata"]["code"], "title": match["metadata"]["title"]} for match in results]
df = pd.DataFrame(result_data)
st.table(df)
else:
st.write("No results found for your query.")
except Exception as e:
st.error(f"An error occurred: {e}")
if __name__ == "__main__":
main()
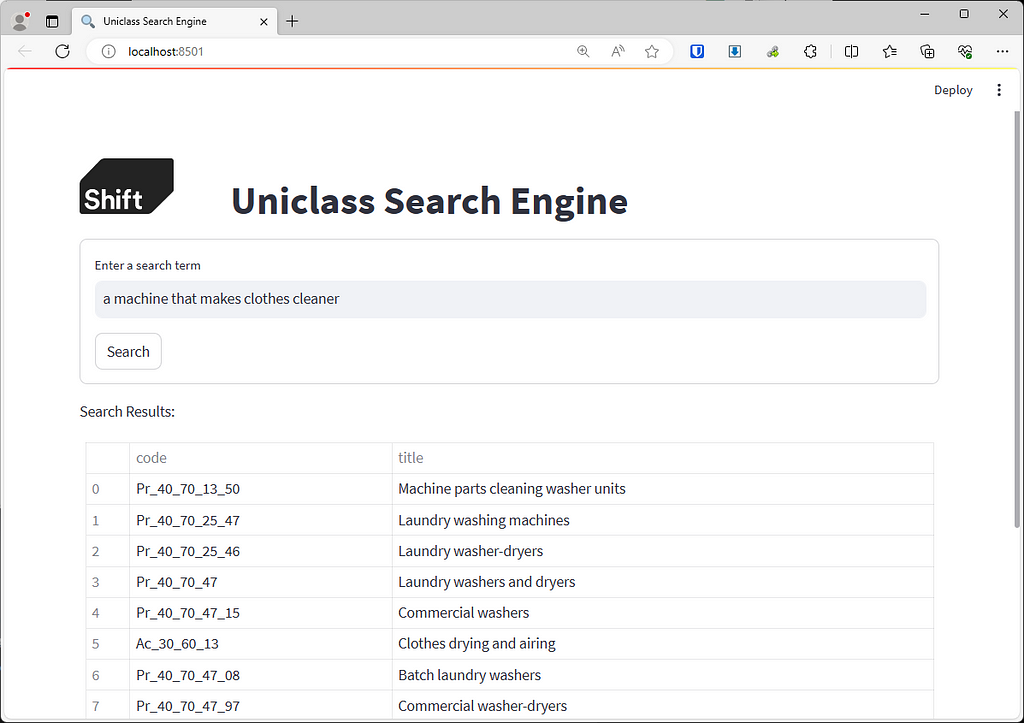
Which results in a lovely AI powered search engine that gives us the correct answer:
Subscribe here on on LinkedIn for the next chapters in this story as I make the searching more intelligent and automate IFC classification.
Creating an AI powered Uniclass classification engine. Part 1: Search Engine was originally published in Shift Construction on Medium, where people are continuing the conversation by highlighting and responding to this story.